

PH Mota
RedatorJornalista há 15 anos, teve uma infância analógica cada vez mais conquistada pelos charmes das novas tecnologias. Do videocassete ao streaming, do Windows 3.1 aos celulares cada vez menores.
Quando o ChatGPT surgiu em novembro de 2022, a OpenAI parecia imbatível. E, em grande parte, era. Esse chatbot, apesar de seus erros e limitações, inaugurou uma categoria própria. No entanto, no setor de tecnologia, as vantagens raramente são permanentes e, em 2026, a posição da empresa liderada por Sam Altman estará bem diferente da que ocupava naquela época.
O Google conseguiu atrair o público em geral com o Nano Banana Pro, enquanto o Gemini vem ganhando terreno de forma constante como um chatbot de inteligência artificial. Ao mesmo tempo, a participação de mercado do ChatGPT caiu consideravelmente em alguns mercados. O Anthropic, por outro lado, consolidou-se como referência em engenharia de software e tornou-se uma das ferramentas preferidas entre os programadores.
Nessa corrida para ditar o ritmo da IA, testemunhamos um movimento curioso: a chegada quase simultânea de dois modelos focados em programação, o GPT-5.3-Codex e o Claude Opus 4.6. A coincidência não parece acidental e reflete o quanto os principais players do setor competem para definir o próximo passo, em um cenário onde os principais beneficiários são, mais uma vez, os usuários.
Com esses novos modelos já disponíveis, a questão que se coloca é: qual a sua real contribuição? Há muitas promessas e benchmarks comparáveis também começam a surgir para ajudar a situá-las. Portanto, é hora de analisar com mais detalhes o que a OpenAI e a Anthropic propõem para aqueles que usam IA como ferramenta de desenvolvimento.
GPT-5.3-Codex e Opus 4.6 entram em cena: o que cada um promete aos desenvolvedores
O GPT-5.3-Codex é apresentado como um modelo focado em agentes de programação que busca expandir o escopo do que um desenvolvedor pode delegar à IA. A OpenAI afirma que ele combina melhorias no desempenho do código, raciocínio e conhecimento profissional em relação às gerações anteriores e que é 25% mais rápido.
Com esse equilíbrio, o sistema é orientado para tarefas prolongadas que envolvem pesquisa, uso de ferramentas e execução complexa, mantendo também a possibilidade de intervir e guiar o processo em tempo real sem perder o fio da meada.
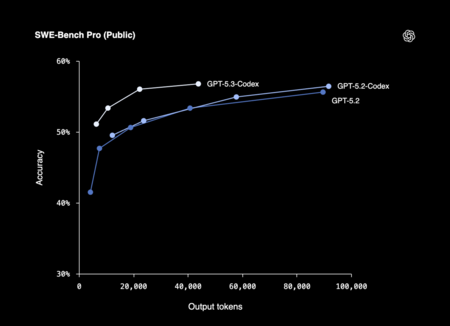
Um dos elementos mais marcantes que a OpenAI destaca nesta geração é o papel que o próprio Codex teria desempenhado em seu desenvolvimento. A equipe utilizou versões iniciais do modelo para depurar o treinamento, gerenciar a implantação e analisar os resultados de testes e avaliações, uma abordagem que acelerou os ciclos de pesquisa e engenharia.
Além desse processo interno, o GPT-5.3-Codex também demonstra progresso em tarefas práticas, como a criação autônoma de aplicativos web e jogos. A empresa publicou dois exemplos que podemos experimentar agora mesmo clicando nos links: um jogo de corrida com oito mapas e um jogo de mergulho para explorar recifes.
A Anthropic chega com o Claude Opus 4.6, uma atualização que a empresa apresenta como uma melhoria direta no planejamento, autonomia e confiabilidade em grandes bases de código. O modelo, segundo eles, consegue manter tarefas autônomas por mais tempo, revisar e depurar seu próprio trabalho com mais precisão.
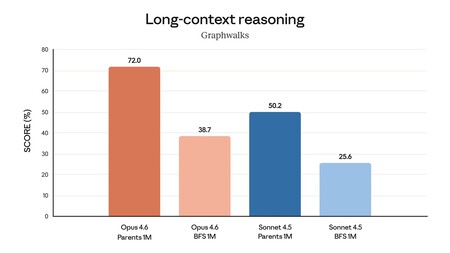
A ideia é que possamos usar essas capacidades em tarefas como análise financeira, pesquisa documental ou criação de apresentações. Além disso, há uma janela de contexto de até um milhão de tokens em versão beta, um avanço que busca reduzir a perda de informações em processos longos e reforçar a utilidade do sistema.
Além do núcleo do modelo, a Anthropic acompanha o Opus 4.6 com uma série de mudanças que visam prolongar sua utilidade em fluxos de trabalho reais. Entre elas, estão mecanismos como o chamado "pensamento adaptativo", que permite ao sistema ajustar automaticamente a profundidade de seu raciocínio de acordo com o contexto.
Também estão disponíveis níveis de esforço configuráveis e técnicas de compressão de contexto projetadas para sustentar longas conversas e tarefas sem esgotar os limites disponíveis. Além disso, equipes de agentes podem ser coordenadas em paralelo dentro do Claude Code e há uma integração mais profunda com o Excel ou PowerPoint.
Algumas empresas tiveram acesso antecipado ao novo modelo da Anthropic. A empresa reúne alguns depoimentos em seu site. Aqui está um deles:
"Claude Opus 4.6 resolveu 13 problemas de forma autônoma e atribuiu 12 problemas aos membros certos da equipe em um único dia, gerenciando uma organização de cerca de 50 pessoas em 6 repositórios. Ele lidou com decisões tanto de produto quanto organizacionais, sintetizando o contexto em múltiplos domínios, e soube quando recorrer a um profissional." Yusuke Kaji, Diretor de IA da Rakuten
Embora o produto da OpenAI, GPT-5.3-Codex, ainda não esteja disponível em APIs, o da Anthropic está. Ele mantém o preço base de US$ 5 por milhão de tokens de entrada e US$ 25 por milhão de tokens de saída, com nuances como um custo adicional quando as solicitações excedem 200.000 tokens.
Medindo quem vence com números?
Ao tentar comparar o GPT-5.3-Codex e o Claude Opus 4.6, o principal obstáculo não é a falta de dados, mas a dificuldade de correspondência entre eles. Cada empresa seleciona avaliações que melhor refletem seu progresso e, embora muitas pertençam a categorias semelhantes, diferem em metodologia, versões ou métricas, o que impede uma leitura direta.
Nesse tipo de modelo, essa fragmentação de resultados faz parte do próprio estado da arte, mas também exige uma interpretação prudente que separe as demonstrações técnicas do verdadeiro potencial. Somente a partir desse filtro é possível identificar os poucos pontos em que ambos os sistemas podem ser medidos em condições comparáveis e extrair conclusões úteis para os desenvolvedores.
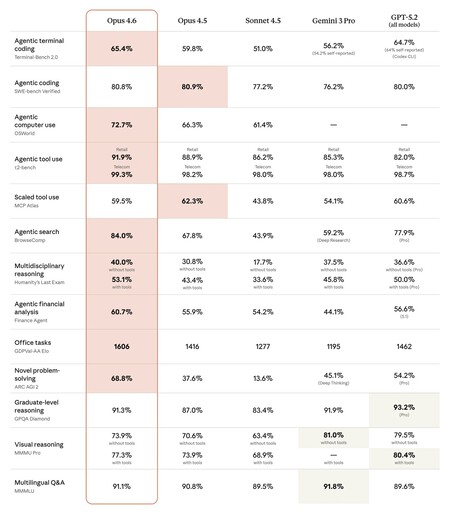
Se restringirmos a análise a métricas verdadeiramente comparáveis, o ponto em comum entre o GPT-5.3-Codex e o Claude Opus 4.6 se limita a duas avaliações específicas identificadas por meio de nossa própria pesquisa: Terminal-Bench 2.0 e OSWorld em sua versão verificada.
Os resultados mostram uma distribuição de pontos fortes, em vez de uma supremacia clara. O GPT-5.3-Codex atinge 77,3% no Terminal-Bench 2.0, contra 65,4% do Opus 4.6, indicando maior eficiência em fluxos de trabalho centrados no terminal. Por outro lado, o Opus 4.6 alcança 72,7% no OSWorld, superando os 64,7% do GPT-5.3-Codex em tarefas gerais de interação com o sistema, um contraste que reforça a ideia de especialização de acordo com o ambiente de uso.
Portanto, podemos dizer que as capacidades descritas por cada fabricante apontam para ferramentas que não são mais limitadas. para gerar código, mas buscam participar de processos prolongados de análise, execução e revisão em ambientes profissionais reais. Essa transição introduz novos critérios de escolha que vão além do desempenho pontual.
Ver 0 Comentários