

PH Mota
RedatorJornalista há 15 anos, teve uma infância analógica cada vez mais conquistada pelos charmes das novas tecnologias. Do videocassete ao streaming, do Windows 3.1 aos celulares cada vez menores.
Dizer que as máquinas não pensam é uma ilusão. Não somos nós que dizemos isso, é um grupo de pesquisadores da Apple que acaba de publicar um estudo revelador intitulado exatamente assim ("A ilusão do pensamento"). Nele, os especialistas analisaram o desempenho de vários modelos de IA com a capacidade de "raciocinar", e suas conclusões são impressionantes... e preocupantes.
Quebra-cabeças para IAs que "raciocinam"
O normal ao avaliar a capacidade de um modelo de IA é usar benchmarks com testes de programação ou matemática, por exemplo. Em vez disso, a Apple criou vários testes baseados em quebra-cabeças lógicos que eram totalmente novos e, portanto, não podiam fazer parte do treinamento desses modelos. Claude Thinking, DeepSeek-R1 e o3-mini participaram da avaliação.
Modelos com falhas
Em seus testes, eles descobriram que todos esses modelos de raciocínio acabavam se chocando contra uma parede ao se depararem com problemas complexos. Nesses casos, a precisão desses modelos caía vertiginosamente para 0%. Não importava que você desse a esses modelos mais recursos ao tentar resolver esses problemas. Se eles apresentassem alguma dificuldade, não conseguiam lidar com a situação.
IAs se cansam de pensar
Na verdade, algo curioso aconteceu. À medida que os problemas se tornavam mais complexos, esses modelos começavam a pensar não mais, mas menos. Eles usavam menos fichas para resolvê-los e desistiam mais cedo, apesar de poderem usar recursos ilimitados.
Nem mesmo com ajuda
Os pesquisadores da Apple até tentaram dar aos modelos um algoritmo exato que os guiasse para encontrar a solução passo a passo. Aqui, outra grande surpresa: nenhum dos modelos conseguiu resolver os problemas, apesar de terem essas soluções guiadas. Eles não conseguiam seguir as instruções de forma consistente.
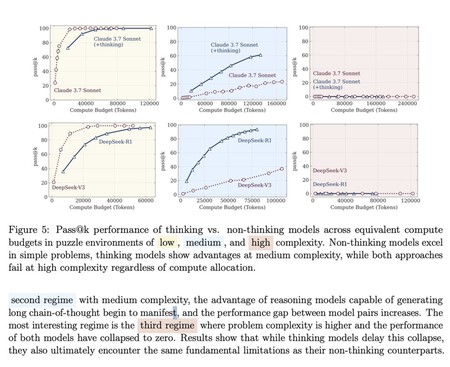 Estes gráficos mostram as diferenças entre os modelos que não raciocinam (DeepSeek-V3) e aqueles que raciocinam (DeepSeek-R1) em problemas de baixa (amarelo), média (azul) e alta (vermelho) complexidade. Há apenas vantagens em "raciocinar" em problemas de dificuldade média. Nos de alta, os modelos simplesmente entram em colapso. Fonte: Apple.
Estes gráficos mostram as diferenças entre os modelos que não raciocinam (DeepSeek-V3) e aqueles que raciocinam (DeepSeek-R1) em problemas de baixa (amarelo), média (azul) e alta (vermelho) complexidade. Há apenas vantagens em "raciocinar" em problemas de dificuldade média. Nos de alta, os modelos simplesmente entram em colapso. Fonte: Apple.
Três tipos de problemas
Em sua avaliação, os pesquisadores dividiram os problemas a serem resolvidos em três classes e verificaram se os modelos de raciocínio realmente contribuíam em algo em comparação com os modelos tradicionais que não "raciocinam".
- Problemas de baixa complexidade: os modelos de raciocínio superaram efetivamente aqueles que não tinham essa capacidade de raciocínio. Frequentemente, eles pensam demais para resolver esses problemas simples.
- Problemas de média complexidade: ainda havia alguma vantagem sobre os modelos convencionais, mas não em excesso.
- Problemas de alta complexidade: todos os modelos acabaram se deparando com esses problemas.
Pensar, nada
Segundo os pesquisadores, a razão para essa falha em raciocinar sobre problemas complexos é simples. Esses modelos não "raciocinam" de forma alguma, e tudo o que fazem é usar técnicas avançadas de reconhecimento de padrões para resolver problemas. Isso não funciona com problemas complexos, e é aí que os fundamentos desses modelos desmoronam completamente. Diante desses problemas, se um modelo recebe instruções claras e mais recursos, ele deveria melhorar e ser capaz de tentar resolvê-los, mas este estudo mostra o oposto.
Muito longe da IAG
O que esses resultados sugerem é que a expectativa gerada por esses modelos é injustificada: os modelos de raciocínio atuais simplesmente não conseguem superar uma determinada barreira adicionando dados ou computação. Alguns apontaram como os modelos de raciocínio poderiam ser um possível caminho para a busca pela IAG, mas as conclusões deste estudo revelam que, na verdade, não estamos mais próximos de alcançar modelos que possam ser considerados inteligência artificial geral.
Eles não encontram soluções, eles as memorizam e as copiam.
De fato, o estudo corroborou algo que outros já haviam defendido no passado: esses modelos simplesmente memorizam o conhecimento e reproduzem a solução ao encontrar padrões correspondentes que levam à essa mesmo solução. Assim, esses modelos foram capazes de resolver o famoso problema das torres de Hanói com muitos movimentos, pois, uma vez conhecida a solução, podem aplicá-la sistematicamente. No entanto, em outros quebra-cabeças, eles falharam após alguns movimentos.
Papagaios estocásticos
Muitos dos críticos da IA sempre argumentaram que os modelos generativos de IA, sejam eles racionais ou não, são basicamente papagaios repetindo o que lhes foi ensinado. No caso da IA, eles detectam padrões e são capazes de encontrar/prever a próxima palavra/pixel ao gerar texto ou imagens. O resultado é… geralmente convincente, mas apenas porque se tornaram extremamente bons em detectar esses padrões e responder de forma adequada e consistente. Mas não se trata de um conhecimento novo: é uma repetição do que já se sabe.
Outros especialistas críticos dessas expectativas nos alertam há muito tempo sobre os perigos do antropomorfismo da IA. Subbarao Kambhampti, da Universidade do Arizona, explicou isso, analisando, por exemplo, o processo de "raciocínio" desses modelos e sua "cadeia de pensamento". Usamos verbos como "pensar" quando eles não pensam. Eles também não entendem o que estão fazendo, e isso contamina todas as suposições que fazemos sobre sua capacidade (ou a falta dela).
Não confie no que a IA diz
O comportamento desses modelos confirma o que se sabe desde que o ChatGPT surgiu. Por mais convincentes que esses modelos possam parecer — independentemente de "raciocinarem" ou não —, a realidade é que eles podem cometer erros graves, mesmo quando outros acertos são notáveis. De fato, há casos em que esses modelos surpreendem por sua capacidade de resolver problemas: na Scientific American, um grupo de matemáticos foi superado por um modelo de IA que conseguiu resolver alguns dos problemas matemáticos mais complexos que eles não conseguiam resolver ou que levavam mais tempo para serem resolvidos.
Evidências inconclusivas
Esses resultados também contrastam com os benchmarks realizados recentemente pela EpochAI e que apontavam precisamente para a conclusão oposta: modelos de raciocínio se comportam notavelmente bem com problemas matemáticos realmente complexos. Jaime Sevilla, seu fundador e CEO, explicou que a Apple pode ter usado um contexto menor do que o da solução, o que poderia levar o modelo a entrar em um possível conflito. Além disso, "as chances de erro durante a execução aumentam exponencialmente para soluções longas, mesmo que o modelo raciocine a solução correta e seja altamente confiável". Outros especialistas apontaram o problema de que os modelos "não conseguem produzir tanto" devido aos limites da janela de contexto usada pela Apple.
Imagem | Puzzle Guy