

Victor Bianchin
RedatorVictor Bianchin é jornalista.
Estamos há meses envolvidos na crise da memória, mas talvez haja uma saída. Na semana passada, o Google Research publicou um estudo no qual revela uma técnica chamada TurboQuant. Trata-se de um algoritmo de compressão capaz de reduzir a memória de trabalho dos modelos de IA em até seis vezes, sem perda perceptível de qualidade ou desempenho. Notícias fantásticas para os usuários finais, que veem uma luz no fim do túnel, mas terríveis para as fabricantes dos chips de RAM, para os quais essa era dourada pode estar chegando ao fim.
Para entender o TurboQuant, é preciso entender o que é essa memória que ele consegue comprimir. Quando um modelo de linguagem processa uma conversa longa, ele precisa lembrar o contexto. Cada token processado fica armazenado no chamado KV cache, uma espécie de memória de trabalho que cresce à medida que conversamos. Quanto mais longa for a conversa, mais memória o modelo precisa.
Esse é um dos principais gargalos na etapa de inferência de IA (ou seja, quando usamos os modelos) e também um dos motivos pelos quais os centros de dados precisam de tanta memória RAM ou HBM. O TurboQuant utiliza um método de quantização vetorial nesse cache para conseguir comprimi-lo mantendo a precisão do modelo.
Seis vezes menos memória
O artigo do Google Research afirma que esse método é capaz de reduzir a KV cache em seis vezes, sem diferença perceptível no desempenho em conversas longas. Os pesquisadores apresentarão seus resultados em um evento no mês que vem e explicarão os dois métodos que permitem colocá-lo em prática. Se confirmarem o que já adiantaram, as implicações são enormes: menos memória para inferência significa que os centros de dados podem fazer o mesmo com muito menos hardware/memória.
A descoberta fez com que alguns analistas classificassem isso como o “momento DeepSeek” do Google. Há um ano, a startup chinesa DeepSeek lançou um modelo de IA que competia com os melhores, mas que havia custado muito menos para ser desenvolvido, o que abalou a indústria. Agora, voltamos a um avanço técnico que aponta na mesma direção. Em IA, fazer o mesmo com menos é crucial, dados os enormes recursos que essa tecnologia exige. Há quem já tenha feito testes preliminares com o TurboQuant e confirmado que o método realmente funciona.

O impacto dessa técnica pode ser enorme, algo que já começa a se refletir nas avaliações das ações em bolsa das fabricantes de memórias DRAM e HBM. Empresas como Micron, Samsung, SK Hynix, SanDisk e Kioxia registraram quedas significativas na semana passada em relação às suas altas recentes. Em 18 de março, as ações estavam em torno de 471 dólares, e hoje estão a 357 dólares, o que representa uma impressionante queda de 24,2%. O mesmo aconteceu com as demais fabricantes, que já vinham caindo desde essa data, mas tiveram a queda acelerada pelo lançamento do TurboQuant.
Mas há um porém
A técnica pode ser aplicada teoricamente apenas à fase de inferência, enquanto a fase de treinamento dos modelos de IA não é afetada por esse método de compressão. Assim, durante o treinamento, continuarão sendo necessárias quantidades enormes de memória. Além disso, será preciso esperar que as empresas de IA realmente comecem a aplicar esse sistema, caso se confirme que funciona, e só então poderemos ver o impacto real. Em teoria, isso dará mais margem de manobra às grandes empresas de tecnologia, que poderão reduzir ainda mais os preços por token — mas ainda não está claro se isso acontecerá.
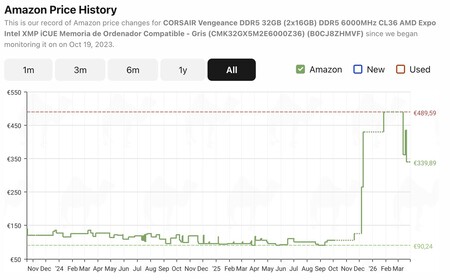
O impacto do TurboQuant coincidiu com algumas quedas nos preços dos módulos de memória. Por exemplo, os módulos Corsair Vengeance DDR5 32 GB 6000 MHz (2x16 GB) estavam a 489,59 euros na Amazon até algumas semanas atrás, segundo o CamelCamelCamel, mas agora estão a 339,89 euros — uma redução significativa.
É verdade que nem todos os componentes estão ficando mais baratos no mesmo ritmo, mas há casos em que as quedas de preço parecem, de fato, estar acontecendo. Vale destacar, no entanto, que o TurboQuant afeta memórias usadas em aceleradores de IA, e não esses componentes para PCs ou notebooks. As quedas observadas provavelmente se devem mais a um ciclo de oferta e demanda desse tipo de semicondutor.
Este texto foi traduzido/adaptado do site Xataka Espanha.
Ver 0 Comentários