

Victor Bianchin
RedatorVictor Bianchin é jornalista.
Claude Mythos Preview é o melhor modelo de IA já criado. Não somos nós que dizemos isso, é a própria Anthropic — mas quase ninguém mais pode afirmar o mesmo, já que apenas um grupo seleto de empresas tem acesso a esse modelo. As capacidades do sistema na área de cibersegurança parecem ser impressionantes, mas cada vez mais especialistas afirmam que, embora o Mythos seja melhor que seus predecessores, não representa o salto revolucionário que a Anthropic sugere. Será que essa forma de lançar o modelo é apenas uma maneira eficaz de criar hype?
O conhecido empreendedor e analista Gary Marcus deu recentemente três razões pelas quais, segundo ele, o lançamento do Mythos não é tão revolucionário quanto a Anthropic quer fazer parecer. Ele citou publicações de engenheiros de software e especialistas em cibersegurança que colocam em dúvida as afirmações da empresa.
A companhia divulgou um estudo sobre as capacidades do Claude Mythos Preview que o descreve como uma ferramenta extraordinária para o campo da cibersegurança. Segundo a Anthropic, o modelo seria tão potente que poderia ser muito perigoso se caísse em mãos erradas.
ok i read the cyber part of the mythos model card. some thoughts. 250 "trials" across 50 crash categories but almost every full exploit is a permutation of the same 2 bugs, rediscovered from different starting points not 250 independent attempts. when you get rid of those 2 bugs… pic.twitter.com/5WsDne1FTj
— gum (@gum1h0x) April 8, 2026
Entre os feitos do Claude Mythos, a Anthropic destacou como ele havia encontrado vulnerabilidades no Firefox 147. Mas, na realidade, muitas dessas falhas são basicamente variações dos mesmos dois bugs. Se fossem eliminadas da equação, a taxa de eficácia do Mythos para encontrar novos exploits cairia bastante, ficando inclusive abaixo do Opus 4.6.
A Anthropic não esconde esse fato, claro, mas isso faz com que essa capacidade não pareça tão impressionante. Um usuário do X também critica o uso do Cybench como benchmark de cibersegurança, quando o Opus 4.6 praticamente o igualava. Para ele, a escolha de alguns dos testes da Anthropic era discutível por não representar um desafio real para os modelos atuais.
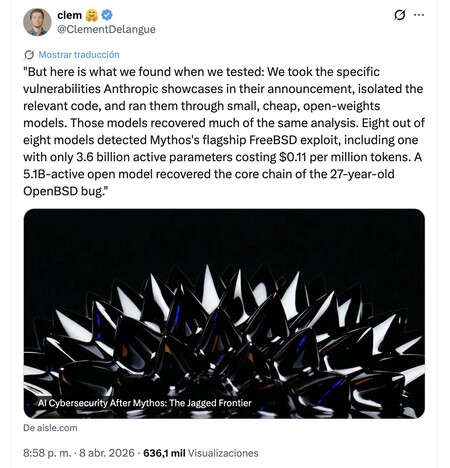
O cofundador e CEO da Hugging Face, Clement Delangue, afirma que o Mythos não é tudo isso. Seu argumento: sua empresa usou modelos abertos pequenos e baratos, isolou o código relevante de alguns exemplos das vulnerabilidades encontradas pelo Mythos e encontrou os mesmos problemas que o modelo da Anthropic já havia detectado.
Viés do observador
Mas, aqui, é preciso destacar que, nessas análises, já se sabia onde procurar porque o Mythos havia encontrado esses problemas antes. Estamos diante do viés do observador e, de fato, no documento da Hugging Face, fica claro que eles chegaram a dar pistas específicas, como “considere o estouro de inteiros”, para que esses erros fossem encontrados. E mais: a Hugging Face não diz que um modelo pequeno possa substituir o Mythos por si só, mas sim que ele pode ser muito eficaz ao receber o trecho de código adequado. O Mythos parece mais capaz de detectar falhas de segurança complexas às cegas, mas isso também porque é um modelo enorme e, por isso, tem maior capacidade. Em outras palavras: o Mythos é melhor porque tem tamanho, design e recursos para isso.
A linguagem utilizada pela Anthropic nesse anúncio pode ser considerada, até certo ponto, um uso claro de FUD (“Fear, Uncertainty, Doubt” → “Medo, Incerteza, Dúvida”) como técnica de marketing. É um recurso que já foi visto no passado e, por exemplo, a OpenAI já afirmou em 2019 — anos antes do lançamento do ChatGPT — que o GPT-2 era perigoso demais para um lançamento público. Obviamente não era, mas isso certamente ajudou a criar expectativa sobre a real capacidade do modelo.
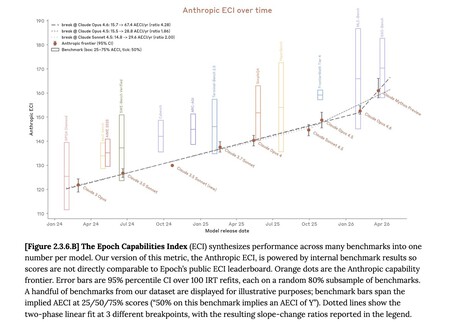
Anthropic's Mythos does not appear to show any acceleration of ECI. After normalizing Anthropic's internal ECI with @EpochAIResearch 's public ECI, it's clear that the two metrics are extremely close, and that Mythos is pretty much on trend, just slightly above GPT 5.4. /1 pic.twitter.com/kZXk5L4XpG
— Ramez Naam (@ramez) April 8, 2026
Os resultados dos benchmarks que a Anthropic publicou deixam claro que, embora haja avanços muito notáveis em alguns testes, em outros a evolução é bem menos impressionante. O Claude Mythos não é o melhor em tudo, e agora surgem analistas que comparam esses dados com outras métricas. Por exemplo, com o Epoch Capabilities Index (ECI), da Epoch AI, a startup que possui um dos benchmarks mais respeitados da indústria. E, segundo esse índice, o Claude Mythos está acima de seus rivais, mas não por uma margem tão grande.
O fato é que o lançamento do Claude Mythos Preview foi realmente chamativo, e os documentos que o acompanharam descrevem um modelo de IA bastante capaz. O problema é que é impossível verificar isso, já que apenas algumas poucas empresas têm acesso a ele e podem testá-lo. Sem essa disponibilidade pública, tudo o que podemos fazer é confiar (ou não) no que a Anthropic diz. Sem uma análise independente, é impossível verificar essas afirmações.
Este texto foi traduzido/adaptado do site Xataka Espanha.
Ver 0 Comentários