

Victor Bianchin
RedatorVictor Bianchin é jornalista.
No dia 24 de fevereiro de 2026, os engenheiros da Anthropic (empresa que faz o Claude) puderam testar pela primeira vez seu novo modelo de inteligência artificial, ao qual deram o nome de Claude Mythos Preview. Assim que o fizeram, perceberam uma coisa:
“demonstrou um salto espetacular em suas capacidades cibernéticas em relação a modelos anteriores, incluindo a capacidade de descobrir e explorar de forma autônoma vulnerabilidades zero-day nos principais sistemas operacionais e navegadores web do mercado”.
Essa descoberta deixou claro para os responsáveis da Anthropic que, embora essa capacidade torne a nova IA muito valiosa para fins defensivos, também representa riscos evidentes caso o modelo seja disponibilizado globalmente. Afinal, um cibercriminoso poderia aproveitá-la para encontrar vulnerabilidades em todo tipo de sistemas e explorá-las.
A empresa detalhou essa análise do Mythos como uma ameaça à cibersegurança em uma publicação em seu blog e destacou como a IA encontrou uma vulnerabilidade (agora corrigida) que estava presente há 27 anos no OpenBSD, um sistema operacional justamente reconhecido por sua altíssima segurança. Houve mais exemplos, e todos deixavam clara a conclusão: o Mythos é poderoso demais para ser usado pelo público em geral.
O melhor da história, segundo os benchmarks
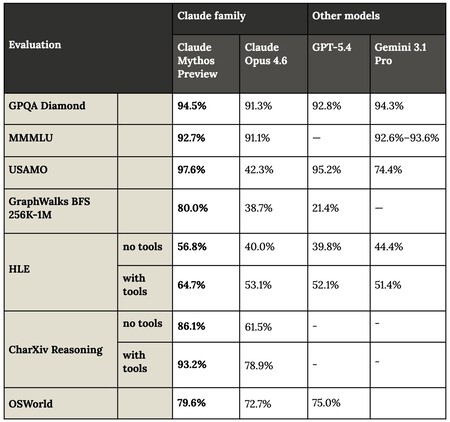
A Anthropic publicou um relatório extremamente detalhado sobre esse modelo, com sua “system card”. Entre os dados apresentados está, por exemplo, o desempenho do Mythos em benchmarks, nos quais ele supera com folga o GPT-5.4, o Gemini 3.1 Pro e também o Claude Opus 4.6, que até então era o melhor modelo do mundo em quase todos os testes de desempenho. Embora, em alguns casos, o avanço não seja tão expressivo, em outros, como no USAMO (resolução de problemas matemáticos), o Mythos atinge praticamente a perfeição.
Nessa “system card”, também se explica em detalhes como o Claude Mythos Preview apresenta uma taxa de alucinações drasticamente inferior à do Claude Opus 4.6 e de modelos anteriores. Ele também é capaz de dizer “não sei” quando não possui informação suficiente para responder, algo que reduz as alucinações causadas por excesso de confiança.

O documento adverte sobre um novo fenômeno: quando o modelo falha em algumas tarefas complexas, as “alucinações” não são erros óbvios, mas sim falhas técnicas extremamente sutis e bem fundamentadas. Isso é perigoso porque a resposta parece totalmente correta até mesmo para especialistas, o que exige uma verificação muito profunda.
Projeto Glasswing
Esse poder e capacidade acarretaram que o modelo tenha sido disponibilizado apenas por meio de um programa “defensivo” chamado Projeto Glasswing, que será exclusivo para alguns parceiros tecnológicos da Anthropic. Especificamente: Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, a Fundação Linux, Microsoft, NVIDIA e Palo Alto Networks. Todas elas terão o privilégio (e a responsabilidade) de acessar o Claude Mythos Preview para identificar vulnerabilidades e exploits e corrigi-los antes que agentes mal-intencionados possam explorá-los.
O Mythos Preview “é apenas o começo”. Embora esse modelo seja o mais avançado já visto até agora, ao menos segundo os benchmarks e dados apresentados pela Anthropic, a empresa afirma que “não vemos razões para acreditar que o Mythos Preview seja o ponto em que as capacidades de cibersegurança dos modelos de linguagem atinjam seu limite”. Eles garantem que esperam que os modelos continuem melhorando nos próximos meses e anos, ainda que este novo modelo já esteja em outro patamar.
Este texto foi traduzido/adaptado do site Xataka Espanha.
Ver 0 Comentários