

PH Mota
RedatorJornalista há 15 anos, teve uma infância analógica cada vez mais conquistada pelos charmes das novas tecnologias. Do videocassete ao streaming, do Windows 3.1 aos celulares cada vez menores.
Desde que o ChatGPT surgiu em novembro de 2022, a corrida pela inteligência artificial tem se intensificado, com um novo modelo aparecendo a cada poucas semanas, prometendo elevar ainda mais o nível. Às vezes, trata-se de uma atualização; outras vezes, de um modelo "carro-chefe" com um nome diferente, mas o padrão se repete: mais poder, mais ambição e uma narrativa cada vez mais global. Nesse contexto, a China está ganhando visibilidade de forma cada vez mais evidente, e o nome que agora surge na conversa é Qwen3-Max-Thinking, a proposta da Alibaba com a qual a empresa pretende competir no mesmo patamar dos grandes nomes do momento.
À primeira vista, o Qwen3-Max-Thinking pode parecer apenas mais um nome na interminável lista de modelos, mas há uma nuance relevante: a empresa o apresenta como seu modelo carro-chefe para tarefas de raciocínio e o coloca explicitamente no mesmo patamar do Gemini 3 Pro. A Alibaba afirma ter escalado parâmetros e investido recursos computacionais em reforço para aprimorar diversas dimensões simultaneamente, desde conhecimento factual e raciocínio complexo até o seguimento de instruções, alinhamento com preferências humanas e capacidades do agente. Em outras palavras, você não está vendendo apenas poder bruto, mas uma maneira melhor de "pensar".
O que os benchmarks ensinam
Para cumprir essa promessa, o mais útil é analisar a tabela comparativa que temos em mãos, com 19 benchmarks e uma contagem direta: Gemini 3 Pro lidera em 11, Qwen3-Max-Thinking lidera em 8. Esses dados, por si só, não decidem "qual é melhor", mas ajudam a entender o tipo de desempenho que a Alibaba demonstra em relação ao Google. Aqui, vale a pena sermos bem literais com o que estamos medindo: cada benchmark se concentra em uma habilidade específica, desde conhecimento geral até programação, uso de ferramentas, seguir instruções ou análise de contexto extenso.
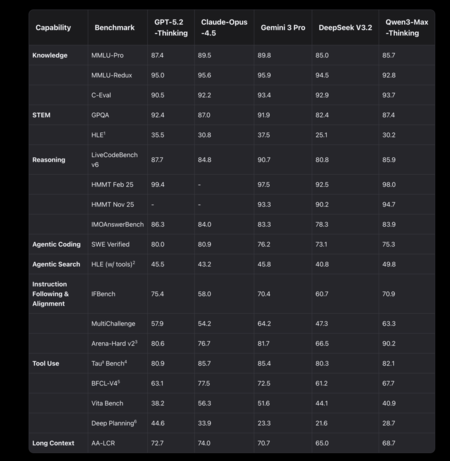
Se analisarmos o ponto em que o Qwen3-Max-Thinking realmente se destaca, há um que se sobressai: seguir instruções e se alinhar com o que os humanos preferem numa conversa. No Arena-Hard v2, Qwen vence com 90,2 contra 81,7 do Gemini, a maior diferença a seu favor em toda a tabela (8,5 pontos a mais). Essa não é uma nuance menor, pois esse tipo de benchmark não premia apenas o "sucesso" técnico, mas o resultado final que uma pessoa considera mais útil ao comparar respostas às cegas. Soma-se a isso o IFBench, onde Qwen vence por uma margem mínima (70,9 contra 70,4). Traduzindo para a vida real: quando o usuário não formula uma instrução perfeita, quando a tarefa é ambígua ou exige a interpretação da intenção, Qwen parece mais orientada a acertar o que lhe é pedido e a fazê-lo de uma forma que pareça natural.
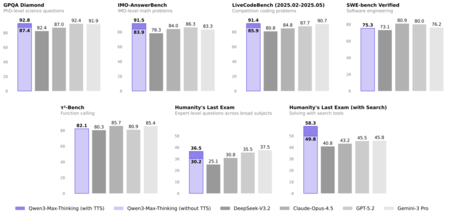
Outro campo em que Qwen sustenta sua narrativa de "modelo de pensamento" é o raciocínio matemático e a resolução lógica de problemas. No HMMT, tanto na edição de novembro de 2025 quanto na de fevereiro de 2025, Qwen se destaca (94,7 contra 93,3 e 98,0 contra 97,5, respectivamente). E no IMOAnswerBench também vence, embora por uma margem mínima: 83,9 contra 83,3. Esses números não sugerem uma vitória esmagadora, mas indicam um padrão consistente: quando o problema exige várias etapas de lógica e não é resolvido apenas com memória ou uma resposta simples, o Qwen tende a se destacar.
A essas melhorias, a Alibaba adiciona um componente que já está se tornando o novo padrão: o modelo não permanece no texto, mas pode agir. Em sua apresentação, a empresa fala sobre um uso adaptativo de ferramentas que permite a recuperação de informações sob demanda e a invocação de um interpretador de código. Essa orientação também aparece nos benchmarks: em HLE (com ferramentas), o Qwen prevalece com 49,8 pontos, comparado a 45,8 do Gemini, o que sugere uma melhor capacidade de desempenho quando o modelo pode ser suportado por ferramentas externas. Aqui, a mudança fundamental é importante: não se trata mais apenas de "o que ele responde", mas de como ele investiga, como decide qual ferramenta usar e como sintetiza o que encontra.
Há um aspecto nesta comparação em que o Gemini 3 Pro parece mais "estruturado" do que "falante", e é precisamente aí que muitos usuários profissionais concentram sua atenção. O modelo do Google se destaca no MMLU-Pro e no MMLU-Redux, dois testes intimamente ligados ao conhecimento geral, bem como no GPQA e no HLE, que aparecem nesta tabela como benchmarks de avaliação exigentes e questões complexas. Em código, o Gemini prevalece no LiveCodeBench v6 e também no SWE Verified, o que reforça a ideia de que, para tarefas de programação, ele ainda é uma opção muito sólida. Além disso, o AA-LCR é líder em análise de documentos longos.
Detalhes se escondem além do preço
Neste ponto, há uma questão tão importante quanto qualquer benchmark: quanto custa usar esses modelos seriamente? Nos preços padrão para 1 milhão de tokens, o contraste é claro. No Gemini 3 Pro, a entrada varia entre US$ 2 e US$ 4, dependendo do lote de tokens, enquanto no Qwen3-Max a entrada custa US$ 1,2. Mas a diferença mais importante aparece na saída, que é onde o "pensamento" do modelo é pago: o Gemini custa de US$ 12 a US$ 18, comparado aos US$ 6 do Qwen. Traduzindo para proporções, no uso padrão, o Gemini é aproximadamente 1,67 vezes mais caro na entrada e 2 vezes na saída, considerando o custo usual. Se o lote ultrapassar 200 mil tokens de entrada, a distância aumenta para 3,33 vezes na entrada e 3 vezes na saída.
Aqui chegamos à parte que geralmente é deixada de lado quando tudo se concentra em poder e preço: o que acontece com seus dados quando você usa o modelo e sob quais regras. No caso do Qwen, dois mundos precisam ser claramente separados. Por um lado, há o chat online para o consumidor, cujos termos contemplam o uso e armazenamento de "Conteúdo do Usuário" para desenvolver e aprimorar tecnologias de IA, incluindo conteúdo anonimizado, e a possibilidade de processá-lo para novos produtos e serviços. Além disso, pelo menos em nossa análise, não encontramos um controle claro ou uma opção visível que permita desativar esse uso. Ademais, não há menção explícita à UE ou ao GDPR no material revisado. Em sua política de privacidade, o Alibaba alerta sobre transferências internacionais de dados e destaca que o serviço é geralmente fornecido a partir de Singapura e que os dados são normalmente processados em Singapura, Indonésia e/ou China.
O Alibaba, no entanto, introduz nuances importantes. O ambiente profissional da Alibaba Cloud garante que não utiliza os dados para treinamento e que criptografa as informações com AES-256. Explica ainda que o tratamento das conversas varia de acordo com o tipo de uso: em chamadas diretas via API, elas não são salvas, enquanto em outros modos o histórico pode ser preservado para melhorar a experiência. O Google apresenta uma nuance semelhante: com as APIs pagas do Gemini, as solicitações e respostas não são utilizadas para treinar modelos e são tratadas como confidenciais. Nesse contexto, é importante destacar outro elemento: a Lei Nacional de Inteligência da China, em seu Artigo 7, estabelece que organizações e cidadãos devem, por lei, "apoiar, auxiliar e cooperar" com o trabalho de inteligência nacional, mantendo também o sigilo das informações obtidas, uma obrigação legal que gerou preocupações na União Europeia e em outras partes do mundo.
Imagens | Xataka com Gemini 3 Pro | Captura de tela
Ver 0 Comentários