

Victor Bianchin
RedatorVictor Bianchin é jornalista.
Há uma nova técnica para treinar modelos de IA de forma supereficiente. Pelo menos é o que parece ter demonstrado o Alibaba, que, na sexta-feira, apresentou sua família de modelos Qwen3-Next, exibindo uma eficiência espetacular que até supera a alcançada pelo DeepSeek R1.
O Alibaba Cloud, divisão de infraestrutura em nuvem do grupo Alibaba, apresentou na sexta-feira uma nova geração de LLMs que descreveu como “o futuro dos LLMs eficientes”. Segundo seus responsáveis, esses novos modelos são 13 vezes menores que o maior modelo lançado pela empresa, que foi apresentado apenas uma semana antes. Você pode testar o Qwen3-Next no site do Alibaba (lembre-se de selecioná-lo no menu suspenso, no canto superior esquerdo).
Qwen3-Next
É assim que se chamam os modelos desta família, entre os quais se destaca especialmente o Qwen3-Next-80B-A3B, que, segundo os desenvolvedores, é até 10 vezes mais rápido que o modelo Qwen3-32B lançado em abril. O realmente notável é que ele consegue ser muito mais rápido com uma redução de 90% nos custos de treinamento.
Segundo o AI Index Report da Universidade de Stanford, para treinar o GPT-4, a OpenAI investiu 78 milhões de dólares em computação. O Google gastou ainda mais no Gemini Ultra e, segundo esse estudo, a cifra chegou a 191 milhões de dólares. Emad Mostaque, fundador da Stability AI, estima que o Qwen3-Next custou apenas 500 mil dólares nessa fase de treinamento. O comunicado oficial do Alibaba não fornece números exatos, mas indica que o Qwen3-Next-80B-A3B usou “apenas 9,3% do custo computacional (horas de GPU) do Qwen3-32B”.
Melhor que seus concorrentes
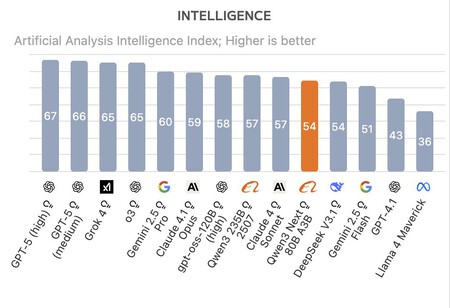
Segundo os benchmarks realizados pela empresa Artificial Analysis, o Qwen3-Next-80B-A3B conseguiu superar tanto a última versão do DeepSeek R1 quanto o Kimi-K2. O novo modelo de raciocínio do Alibaba não é o melhor em termos globais —GPT-5, Grok 4, Gemini 2.5 Pro e Claude 4.1 Opus o superam—, mas, ainda assim, apresenta desempenho excepcional considerando seu custo de treinamento. Como conseguiu isso?
Esses modelos utilizam a arquitetura Mixture of Experts (MoE). Com ela, o modelo é “dividido” em sub-redes neurais (“especialistas”), especializadas em subconjuntos de dados. No caso do Alibaba, o número de especialistas foi aumentado: enquanto DeepSeek-V3 e Kimi-K2 usam 256 e 384 especialistas, respectivamente, o Qwen3-Next-80B-A3B utiliza 512 especialistas, mas ativa apenas 10 ao mesmo tempo.
A chave dessa eficiência está na chamada atenção híbrida. Modelos atuais tendem a ter sua eficiência reduzida quando o comprimento das entradas é muito grande, precisando “prestar mais atenção”, o que implica mais computação. No Qwen3-Next-80B-A3B, utiliza-se uma técnica chamada "Gated DeltaNet", desenvolvida e compartilhada pelo MIT e pela NVIDIA em março.
Essa técnica melhora a forma como os modelos prestam atenção ao fazer certos ajustes nos dados de entrada. A técnica determina quais informações devem ser retidas e quais podem ser descartadas. Isso permite criar um mecanismo de atenção preciso e super eficiente em termos de custo. De fato, o Qwen3-Next-80B-A3B é comparável ao modelo mais potente da Alibaba, o Qwen3-235B-A22B-Thinking-2507.
Os crescentes custos de treinar novos modelos de IA começam a se tornar preocupantes, o que tem levado a esforços cada vez maiores para criar modelos de linguagem “pequenos”, que sejam mais baratos de treinar, mais especializados e especialmente eficientes. No mês passado, a Tencent apresentou modelos com menos de 7 bilhões de parâmetros, e outra startup chamada Z.ai lançou seu modelo GLM-4.5 Air com apenas 12 bilhões de parâmetros ativos. Enquanto isso, os grandes modelos, como GPT-5 ou Claude, usam muito mais parâmetros, o que aumenta significativamente o custo computacional necessário para utilizá-los.
Este texto foi traduzido/adaptado do site Xataka Espanha.