

PH Mota
RedatorJornalista há 15 anos, teve uma infância analógica cada vez mais conquistada pelos charmes das novas tecnologias. Do videocassete ao streaming, do Windows 3.1 aos celulares cada vez menores.
Temos inteligência artificial. O que nos falta é diversidade artificial. Essa é a conclusão a que chegou um grupo de pesquisadores que realizou um teste relativamente simples: eles fizeram uma série de perguntas a 25 modelos diferentes de IA para ver o que eles responderiam. E esse é o problema: eles deram respostas notavelmente semelhantes.
Mente coletiva artificial
Cientistas da Universidade de Washington, da Universidade Carnegie Mellon e da Universidade Stanford, entre outras instituições, publicaram um interessante estudo conjunto. Nele, revelam como, após vários testes, parece claro que, embora os modelos de IA estejam se tornando cada vez mais avançados, o problema é que todos parecem ter desenvolvido uma espécie de "mente coletiva artificial": não importa o que lhes seja perguntado, eles respondem de maneira suspeitosamente semelhante.
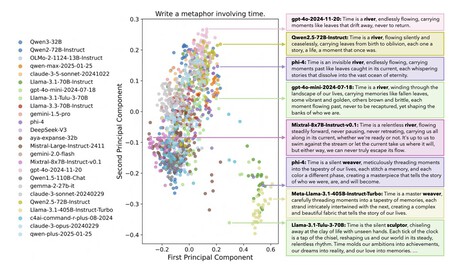 Quando perguntados "o que é o tempo?", muitos modelos responderam com a frase "o tempo é como um rio", enquanto outro grupo de modelos respondeu que "é como um tecelão"
Quando perguntados "o que é o tempo?", muitos modelos responderam com a frase "o tempo é como um rio", enquanto outro grupo de modelos respondeu que "é como um tecelão"
O tempo é um rio
Uma das perguntas feitas a esses modelos foi: "O que é o tempo?" Embora essa pergunta claramente permita respostas muito diferentes, o preocupante é que elas não foram observadas. Vários modelos responderam com a frase "o tempo é um rio" e depois a desenvolveram, enquanto outros responderam com "o tempo é um tecelão (de momentos)". Essa similaridade nas respostas se mostrou constante.
Ilusão da abundância
Acreditamos que, ao consultar uma IA, acessamos um mundo inteiro de possibilidades conversacionais, mas o estudo revela que, na verdade, estamos lidando com um sistema que propõe resultados muito semelhantes. Embora os modelos de linguagem prometam criatividade ilimitada, eles tendem a convergir para uma mente coletiva onde a diversidade é sacrificada em prol da consistência estatística. Isso é compreensível, especialmente considerando que grandes modelos de linguagem são baseados no conceito de um transformador, um sistema probabilístico que tenta encontrar a "melhor" próxima palavra ao responder.
Mesmo roteiro
Os pesquisadores criaram um conjunto de dados em larga escala com 26.000 consultas de usuários reais que, teoricamente, permitiram que os modelos gerassem múltiplas respostas válidas e criativas. Eles chamaram esse conjunto de dados de "Infinity-Chat" e dividiram as perguntas em seis categorias principais e 17 subcategorias.
IA se repete mais do que um disco riscado
Durante os testes, observou-se que o mesmo modelo tendia a se repetir, gerando respostas muito semelhantes. De fato, mesmo quando parâmetros especiais foram usados nas perguntas, elaborados para incentivar a diversidade, o mesmo efeito ocorreu. Isso é o que os pesquisadores chamam de "colapso entre modelos".
Semelhança excessiva
Esses testes deixaram claro que a similaridade semântica — o quão semelhantes eram as respostas dos diferentes modelos — era preocupante. De acordo com o estudo, essa similaridade variava entre 71% e 82% e, em alguns casos, certos modelos chegaram a gerar parágrafos idênticos, palavra por palavra.
O problema do treinamento
Não se trata apenas de todos gerarem texto de forma semelhante devido ao seu design, mas também existe um problema de treinamento. Os autores sugerem que essa homogeneidade de respostas pode ser atribuída a diversos fatores:
- Fontes de dados de treinamento compartilhadas: os modelos são treinados com conjuntos de dados semelhantes e, por exemplo, baseiam-se em textos e conhecimentos similares provenientes de fontes como a Wikipédia ou um acervo muito similar de livros.
- Efeito de contaminação por dados sintéticos gerados por outras IAs: elas também utilizam textos sintéticos gerados por outros modelos de IA.
- Recompensas: os modelos usados para recompensar essas IAs são calibrados para premiar uma certa noção de qualidade, o "consenso". Assim, a diversidade criativa e individual é penalizada. As IAs são "treinadas" para serem precisamente muito parecidas umas com as outras.
Um grande problema à frente
Tudo isso leva os pesquisadores a alertarem explicitamente sobre dois riscos claros ao usar esses modelos de IA.
- Pensaremos da mesma forma: se nós, usuários, continuarmos usando modelos de IA que nos dão essencialmente as mesmas respostas, nossas próprias maneiras de pensar sobre esses tópicos e problemas se tornarão "homogeneizadas", e nossas respostas também se tornarão mais uniformes.
- Redução de pontos de vista: o outro perigo se origina do primeiro. Se a IA eventualmente convergir e responder da mesma maneira, diferentes perspectivas serão eliminadas. Aqui, vieses do mundo ocidental, por exemplo, se tornarão evidentes em modelos ocidentais (ChatGPT, Gemini, Claude), e o mesmo acontecerá com modelos orientais, por exemplo. Isso poderia levar à potencial supressão de visões de mundo, perspectivas e percepções alternativas da nossa realidade que diferem das predominantes.
Imagem | Solen Feyissa
Ver 0 Comentários